







Please Read the Terms of Service (Often)
I was going to call this “please read the fine print” but the reality is that since we’re no longer dealing with printed words on paper, we’re no longer really talking about fine print. We can make the font on our screen as large as we want it. And those far-reaching terms are no longer being hidden in the middle of contracts in tiny print. The information is there, in black-and-white, on the screen, in simple terms.
Almost like they actually want us to see it. To see just how much information (and control over that information) we’re giving them.
Image: Bfishadow via Flickr
Yet they know that very few people read those contracts before they hit “agree.”
After all, it would take an average user 180 hours per year to read through all the terms and conditions for the sites he/she accesses. Think about how many sites you go on daily. Not just the ones where you’ve stored an account; every place you visit on the Web.
Gulp.
I think this is an important but uncomfortable topic. My mind has been turning it over by myself for the last few days. Now I’m dumping everything I’m thinking about on you. I’ll also preface this by saying that I just finished the Hunger Games. That may be clouding my thoughts.
Hopefully you’ll take the time to read through this post and join the conversation.
*******
A few nights ago, Josh and I watched the documentary Terms and Conditions May Apply. Josh jokingly told me about it, saying that it fed into my “it’s not paranoia if they actually are out to get you” mentality. He’s teasing but I am someone who reads contracts very very seriously and obviously likes to discuss this a lot.
I think a lot about what I put on the Web as well as even in private communication such as email or text message. Because it is scanned. The Internet is archived. It goes beyond our archived Tweets at the Library of Congress or the fact that it is impossible in most cases to actually remove an account in its entirety from a site such as Facebook. It goes into the fact that even if it looks as if it’s gone, it’s really not gone.
For instance, when you permanently delete your account at Facebook, you are stopping yourself and other users from being able to access your information. But what about Facebook itself? Can they still access your information? They are completely honest and open about it: yes.
-
You will not be able to regain access to your account again.
-
Most personally identifiable information associated with it is removed from our database. This includes information like your email address, mailing address, and IM screen name. Some personally identifiable information may remain, such as your name if you sent a message to someone else. [Most and some are vague terms, no?]
-
Copies of some material (photos, notes, etc.) may remain in our servers for technical reasons, but this material is disassociated from any personal identifiers and completely inaccessible to other people using Facebook. [Note: While inaccessible to users, Facebook keeps these items of an indeterminate amount of time. And as someone said in the film, anything that can be disassociated can also be reassociated down the line if the TOS changes, as if often does.]
See, I’m not being paranoid… right? Okay, yes, I sound like I’m about to go off the grid, but please read on because the reality is that I DO have a Facebook account, a Twitter account, a blog, email, etc. I use TOS mostly to think about the way I use sites vs. not using them at all. And at this point, as the twins move online, I’m thinking about it in overdrive as we try to teach them what to post, email, text, and what to save for face-to-face conversations.
*******
So what is my biggest fear that stems from thinking about the TOS of online sites and mobile devices?
Let’s start with this: once something goes out, you really don’t have a way of getting it back. I’m not just talking about blog posts. This is true for the pictures we send, the emails we write, our text messages, and even Siri searches. If you think about that too long and hard, your stomach (if it’s like mine) will start hurting. I mean, yes, we all practice circumspection, but how can we know what society will be like in the future? Or how my own opinions will change?
Things that are neutral today could become a marker tomorrow. All profiling has a first day of profiling; a moment beforehand where we’re not profiling, and all the moments afterward when we do.
See, gulp.
What if Candy Crushing becomes anathema in the future?
*******
Every blog post I write goes out in an RSS feed and gets delivered to blog readers. If I delete the post, every reader subscribed to me still has a copy in their RSS-feed reader. If I delete an image, it’s still there too. My blog (like all of our blogs) has been archived by the Wayback Machine. Mine has been archived 172 times. Again, it means you can pretty much access it forever regardless of what I do on my end.
Not really a big deal on one hand because I mostly talk about Candy Crush. But what if I wrote about more controversial topics than speckled doughnuts?
It’s more what I DON’T know that worries me since we all know that there is plenty that we don’t know. It’s the stuff that pops up in the news. It’s the TOS that change overnight without warning. The stuff that we’ve all sort of assumed but still cringe when it’s confirmed. How are they using my data? Mostly to sell stuff to me or to sell stuff to others, by the way it sounds. But these sites are collecting a shit-ton of data, and we — the users — are their assets. That’s how the value of a company such as Facebook was decided before it went public: what are its assets? People and their data.
Do they really need all of that information? Or is any information valuable and thereby sell-able in the future? Someone will want it. So even if Facebook is only using it to target ads, how will the people they pass my information along to the future use it?
I am a careful Internet and mobile device user, but even I know that most of my caution is a moot point: the information is being collected. Even if I opt-out of the online world, I still need to contend with three billion other ways my data is being collected from what I order at restaurants to what I buy with my credit card. Is there any point in trying to hold onto a shred of privacy in a world that is somewhat determined to ensure that I have no privacy?
Maybe?
Should we hold particularly tightly to those shreds of privacy since we know they’re mostly an illusion? And how tightly?
*******
The documentary Terms and Conditions May Apply is a little choppy. Sometimes it felt a little more akin to a 20/20 special report than a movie. Sometimes it veered a little too much into the mood music. But still, it’s a good starting point to show the twins to drive home the idea that even their silly Siri conversations are being cataloged somewhere. And all those data points, while made “anonymous” in theory, can easily be made deanonymized now by a little poking, or by the company itself down the road.
Knowing what someone searches for online is sort of like knowing their thoughts. Like running your fingers through their brain.
I think a lot about how to make sure that I’m not giving more than I need to. I start with other Internet users out there, and I don’t write things that I don’t feel okay posting and having out there for eternity. It means that I don’t get to discuss things I’d love to unload off my chest and discuss. I don’t put up pictures I’m not okay losing control of as they float through the back-end of various sites. There are plenty of fun things I find that I’d love to post on Facebook or link to on Twitter, but I don’t. Because I like to leave at least a few pieces of the puzzle missing? Does it matter?
And then I think about the companies themselves. I opt-out of a lot of fun things.
A good example is 23 and Me. When I first heard about it, it sounded really cool. Totally up my alley, especially as a health writer. I’d personally love all that cool info, but the company has ties to Google, and we’ve already seen just how seriously Google takes my privacy. As the new president of the board said in Forbes,
Selling kits to consumers is the first phase of that eventual outcome. That is the only aspect of the business model that we’ve announced so far.
Before I try out something potentially risky that provides even more than the normal shit-ton of information we leave on the average Facebook page, I do want to know the whole business model. But even 23 and Me can’t possibly predict how valuable that information will be down the road or how someone with new technology in place will want to use it. And because they know that they can’t predict what sort of gold mine they’re sitting on, they hedge their bets with a pretty scary terms of service and privacy statement that they admit can change at any time:
23andMe may make changes to the TOS from time to time. When these changes are made, 23andMe will make a new copy of the TOS available on its website and any new additional terms will be made available to you from within, or through, the affected Services.
In other words, they can change the copy on their site. They may or may not notify you if they change the language in one of the existing terms. They will only notify you if they add new terms. The onus is on the user to continuously check the TOS. While this is true of many many sites, the sites I tend to use also have a huge user base so I generally hear within a very short period of time if a new TOS has been uploaded. 23 and Me just doesn’t have the user base nor the media watching it like a hawk.
What do I think is the worst that can happen? I don’t even know. I mean, so what if a company out there knows about my genes? What if they tell others? After all, my doctor has a sample of my DNA.
But I guess that’s my fear: the fact that I have so many questions. I have no clue how it may or may not bite me in the ass in the future.
*******
If you’re one of those people who clicks “accept” without diving into the details, first and foremost, don’t panic. I know that sounds ridiculous after I just spent the top portion of this post essentially fomenting you into a panic. But don’t. It’s never too late to gather information and change course.
The documentary is a good place to start. It covers a lot of interesting topics:
- He points out the language you should be wary of in a TOS.
- He talks about how Google said in the past that cookies were anonymous, but changed their policy two years later to admit that they can (and will) turn over that information which isn’t really anonymous if presented with certain legal documents.
- The value of personal data, which is what makes Facebook one of the most valuable companies in the world.
- Companies have no incentive (except to retain users) to make your information private. We may want them to out of common human decency, but the only way that data is actually valuable is if they can use it. An example is how Google merged its services into one very valuable profile.
- Stored Communications Act and third party doctrine.
- The history of Carrier IQ software on phones.
- The concept of retroactive searches carried out on stored data and the construction of Bluffdale
- How Facebook changed its default settings over time…
This is a screenshot from the film of how the default settings looked on Facebook back in 2005.
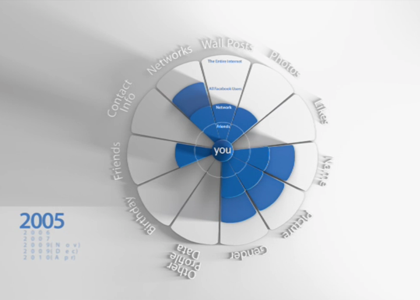
The first ring is stuff you share with friends. The second ring is friends of friends. The third ring is all Facebook users. The fourth ring is the entire Internet. In other words, back in 2005, non-Facebook users could see nothing on Facebook. Facebook users could see someone’s name, where they lived, their gender, and their networks. By default, that is. People could hide those details too. The site was set up for friends of friends to be able to see your wall posts, photos, and friends unless you changed that setting. But overall, if you didn’t quite get how to tweak the settings on Facebook, you weren’t revealing everything with the world.
This is the screenshot from 2010. Still the default privacy settings.
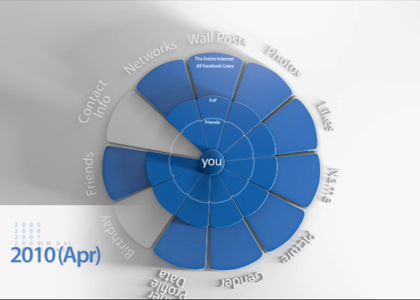
In other words, you no longer need to be a fellow Facebook user to see… everything. Literally everything except your contact info and birthday is part of the default privacy settings. Of course, when they changed the privacy settings overnight without notice on Facebook in 2009, everyone’s information was public until they went back in and adjusted their settings. We all claim that users would revolt if they pulled that again, but the fact is, how many people would leave Facebook when we know that so many other companies are forcing our private information into the public sphere?
I operate under the assumption that nothing is private on the Internet regardless of privacy settings.
*******
There are sites such as Terms of Service, Didn’t Read that break down some general information about various sites. YouTube is a Class D (Class E is the worst, and Class A is the best). Google is a Class C. Soundcloud is a Class B. Twitpic gets a lot of thumbs down with their Class E ranking. Most of the sites are still without ranking since the website is a labour of love by a small team. But you can still gather a lot of information from it.
Such as did you know that iCloud can “pre-screen, move, refuse, modify and/or remove Content at any time, without prior notice and in its sole discretion?” Hope you have a backup. To be fair, telling you to back up your own data is the next section of the TOS. Or that Amazon’s “terms may be changed any time at their discretion, without notice to the user.”
Sigh.
*******
This is a very long post. I know that. But there is a lot that we need to talk about when it comes to how sites are collecting and using data. Is there any solution? Of course not. But there is awareness. And once you have awareness, you can set your own personal boundaries.
And then it’s our job as users to make sure that even if the sites change their own boundaries, that it affects us less than it could have because of the personal boundaries we put around not sharing our information.
So, what do you think? Is there any point in trying to hold onto a shred of privacy in a world that is somewhat determined to ensure that we have no privacy?







8 comments
It feels very overwhelming how much data is flowing everywhere, and I don’t know that anyone has much privacy left.
I am careful with what I share online. I assume that anything on the internet (including private chats, messages, or things in secret groups or message boards) could be visible to anyone at anytime, and share accordingly.
The problem is going back…to our younger, less aware days. I am very careful with what I share online but I wasn’t always. Back when Facebook was safer and I was younger… And I know that just because it was safe back then doesn’t mean that info isn’t out there now.
Half of me wants to move into a shack in the woods where no one will infringe on my privacy, but the other – more logical (haha) – side realizes that this is the world we live in and the only thing we can do is be more aware, and think twice about what we share online.
It’s just a little less work to get the information these days. We’ve gone from small towns where everyone knows each other to large cuties where everyone is still in the phone book to the internet where someone has electronic access to your information.
I have some paranoia – I don’t do any mobile banking and usually giv my work number when a phone number is required. And I have good reason to seek anonymity due to my job. But I know it’s mostly an illusion – I’m just not making it too easy for people to find me.
This post made me think of Beaudrillard’s “The Intelligence of Evil”…not just that corporations are invading our privacy, but that we’re so willing to put it out there on Facebook and other sites. We give up our identities for a brand that we create of ourselves. Building images of ourselves is easier than ever… So even if ‘they’ find us, it’s not the real us anyhow.
I work in financial services compliance (oh the joy). I spend a lot of time discussing what disclaimers need to go where etc (because i am the lucky one who gets to review them). Consequently, i do skim through a lot of T& C- i know what nasties can be hiding in there.
Australia is in the process of implementing new privacy laws around a lot of these issues (that’s the next big project at work). I think that at least some of the change is going to come from governments saying “just because you can do this, doesn’t mean that you should- so illegal” Difficult balance to enforce, but if people are aware, they do take measures.
I had a couple of early experiences with internet privacy issues- apparently my fisrts name middle name is a common combo, as is my first name last name. As an early adopter, I snagged those combinations in both hotmail and gmail. I get emails directed at people with similar, but not the same email handle (including a shirt order for a police constable.) I generally make an effort to contact them (the emails are ones on key items, or contain sensitive info). Generally, pretty horrified to realise how easy it is to send a total stranger an email with such personal details.
I’m sighing with you now. Oy, what have I done.
This literally gave me the shivers: “Like running your fingers through their brain.”
mhm, let me see. Not on FB, no creditcard, no online shopping, blog not in my real name, multiple email addresses /bank accounts and still very careful what I put online. Yes, I care about the last bits of privacy. And don’t consider myself paranoid. I work with telecom data and I know how much effort it is for a company to ‘depersonalise’ data. And how little thought is behind it. And oh hey, government ALSO mandates we keep tons of data, you know, for national security reasons.
BUT, disc space is not unlimited (and commercial disc space a lot more expensive than one would think)
I don’t know, I’ll keep using cash a bit more, I’ll walk/cycle a while longer and will only/mostly use duckduckgo to search for sensitive information on the web.
Oh boy, this tapped into my inner conspiracy-theorist. I would like to go back to sticking my head in the sand. That being said, I’m much more careful about the information I post on my blog, f-b, and I don’t tweet. However, we have a public website for adoption and a Facebook community page. It freaks me out that this is what it’s come to, but in the Internet age I have no idea how to NOT put our info out there. I use google almost exclusively too and let myself be blissfully ignorant…if they don’t care about my privacy than Microsoft probably doesn’t either.